Author
Abstract
This is a short tutorial on the following topics using Gaussian Processes: Gaussian Processes, Multi-fidelity Modeling, and Gaussian Processes for Differential Equations. The full code for this tutorial can be found here.
Gaussian Processes
A Gaussian process
is just a shorthand notation for saying
A typical choice for the covariance function is the square exponential kernel
where are the hyper-parameters.
Training
Given the training data , we make the assumption that
Consequently, we obtain
where . The hyper-parameters and the noise variance parameter can be trained by minimizing the resulting negative log marginal likelihood
Prediction
Prediction at a new test point can be made by first writing the joint distribution
One can then use the resulting conditional distribution to make predictions
Illustrative Example
The following figure depicts a Gaussian process fit to a synthetic dataset generated by random perturbations of a simple one dimensional function.
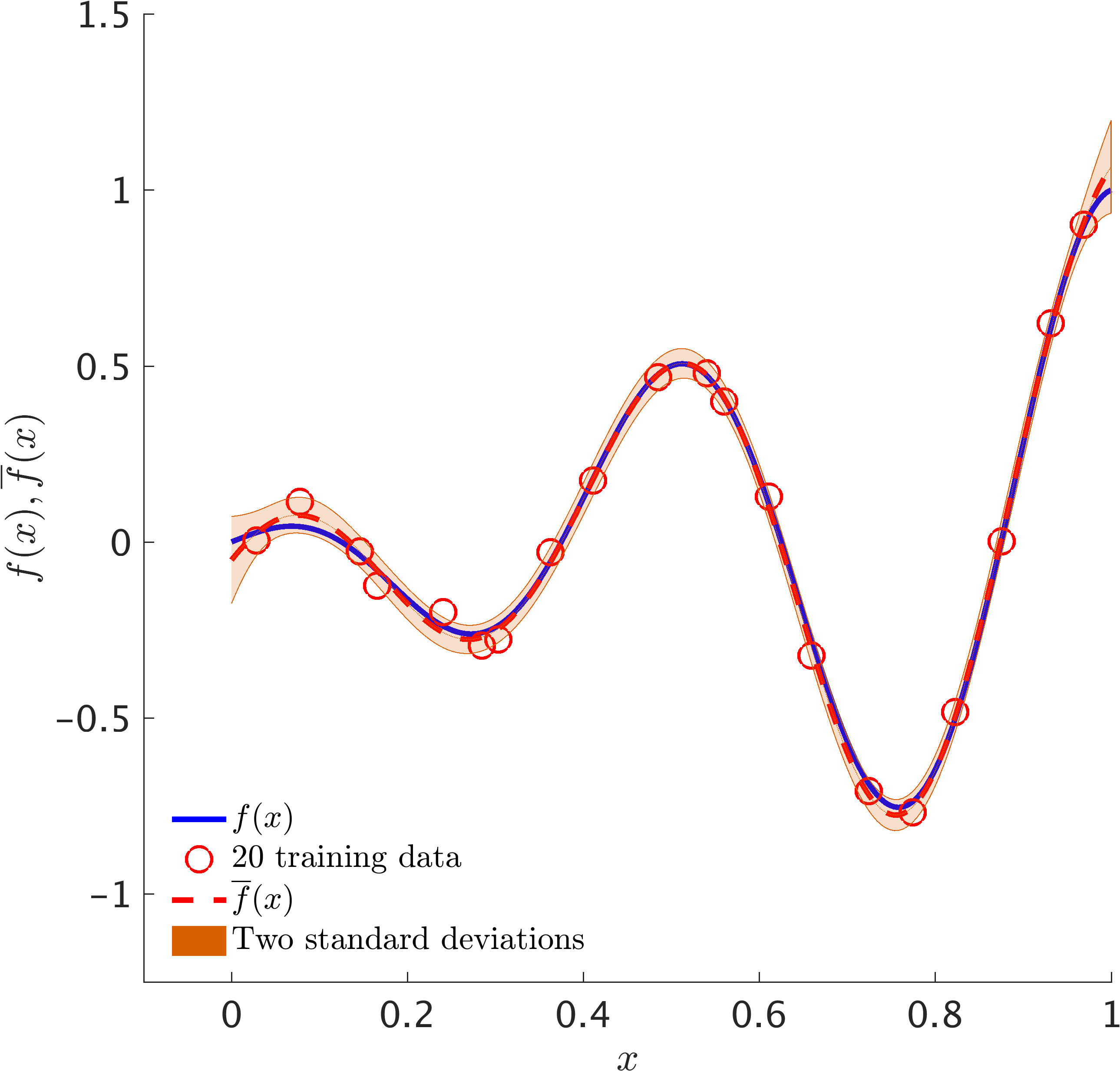
Illustrative Example: Training data along with the posterior distribution of the solution. The blue solid line represents the true data generating solution, while the dashed red line depicts the posterior mean. The shaded orange region specifies the two standard deviations band around the mean.
Multi-fidelity Gaussian Processes
Let us start by making the assumption that
are two independent Gaussian processes. We model the low fidelity function by and the hight-fidelity function by
This will result in the following multi-output Gaussian process
where
Training
Given the training data and , we make the assumption that
and
Consequently, we obtain
where
and
The hyper-parameters and the noise variance parameters can be trained by minimizing the resulting negative log marginal likelihood
Prediction
Prediction at a new test point can be made by first writing the joint distribution
where
One can then use the resulting conditional distribution to make predictions
Illustrative Example
The following figure depicts a multi-fidelity Gaussian process fit to a synthetic dataset generated by random perturbations of two simple one dimensional functions.
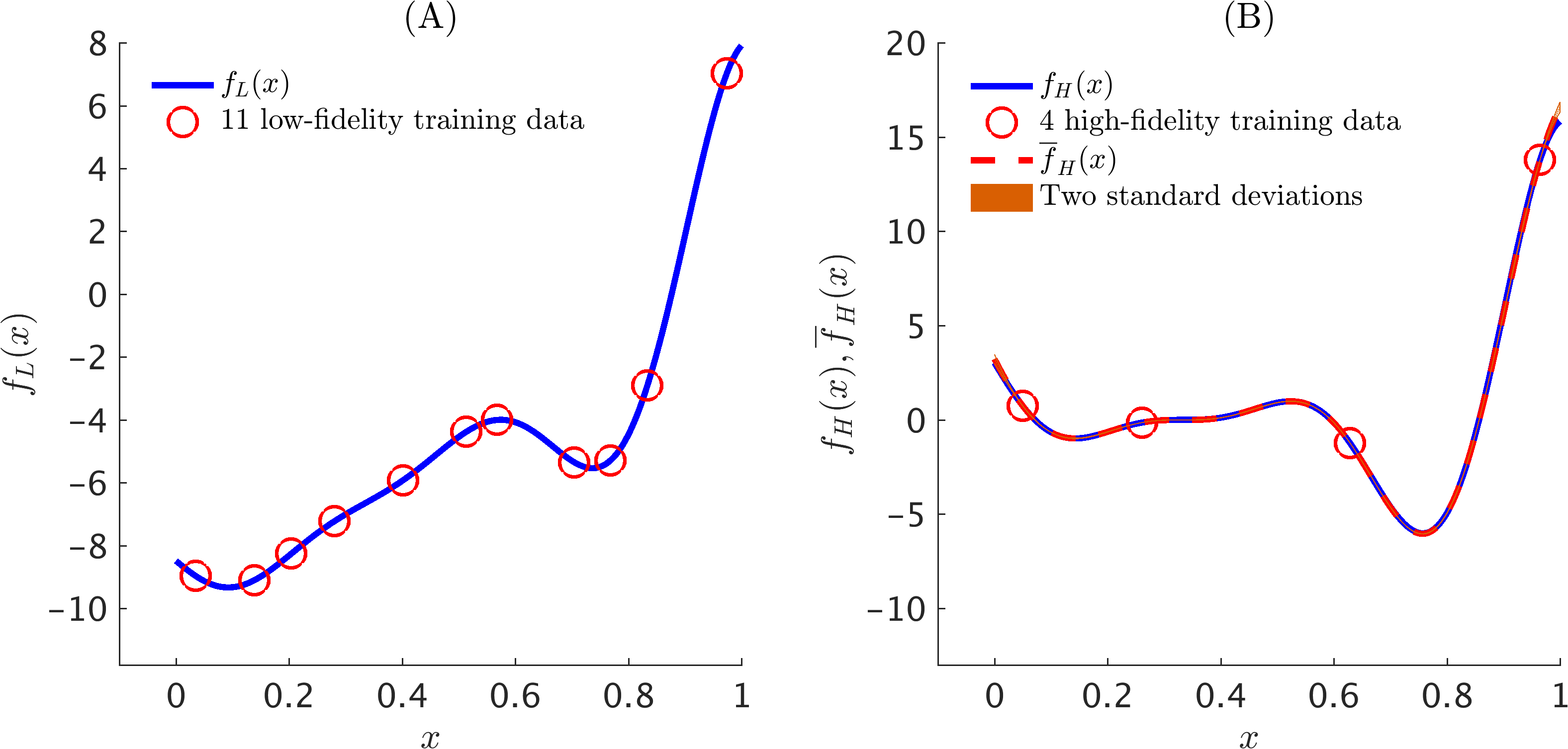
Illustrative Example: (A) Training low-fidelity data along with the true data generating low-fidelity function. (B) Training high-fidelity data along with the posterior distribution of the solution. The blue solid line represents the true data generating high-fidelity function, while the dashed red line depicts the posterior mean. The shaded orange region specifies the two standard deviations band around the mean.
Machine Learning of Linear Differential Equations using Gaussian Processes
A grand challenge with great opportunities facing researchers is to develop a coherent framework that enables them to blend differential equations with the vast data sets available in many fields of science and engineering. In particular, here we investigate governing equations of the form
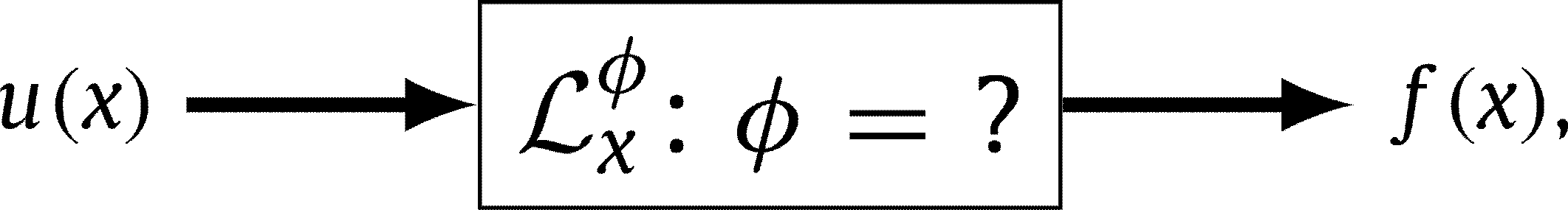
where is the unknown solution to a differential equation defined by the operator , is a black-box forcing term, and is a vector that can include space, time, or parameter coordinates. In other words, the relationship between and can be expressed as
Prior
The proposed data-driven algorithm for learning general parametric linear equations of the form presented above, employs Gaussian process priors that are tailored to the corresponding differential operators. Specifically, the algorithm starts by making the assumption that is Gaussian process with mean and covariance function , i.e.,
where denotes the hyper-parameters of the kernel . The key observation here is that any linear transformation of a Gaussian process such as differentiation and integration is still a Gaussian process. Consequently,
with the following fundamental relationship between the kernels and ,
Moreover, the covariance between and , and similarly the one between and , are given by , and , respectively.
Training
The hyper-parameters and more importantly the parameters of the linear operator can be trained by employing a Quasi-Newton optimizer L-BFGS to minimize the negative log marginal likelihood
where , , and is given by
Here, and are included to capture noise in the data and are also inferred from the data.
Prediction
Having trained the model, one can predict the values and at a new test point by writing the posterior distributions
with
where
Note that, for notational convenience, the dependence of kernels on hyper-parameters and other parameters is dropped. The posterior variances and can be used as good indicators of how confident one could be about predictions made based on the learned parameters .
Example: Fractional Equation
Consider the one dimensional fractional equation
where is the fractional order of the operator that is defined in the Riemann-Liouville sense. Fractional operators often arise in modeling anomalous diffusion processes and other non-local interactions. Their non-local behavior poses serious computational challenges as it involves costly convolution operations for resolving the underlying non-Markovian dynamics. However, the machine leaning approach pursued in this work bypasses the need for numerical discretization, hence, overcomes these computational bottlenecks, and can seamlessly handle all such linear cases without any modifications. The algorithm learns the parameter to have value of .
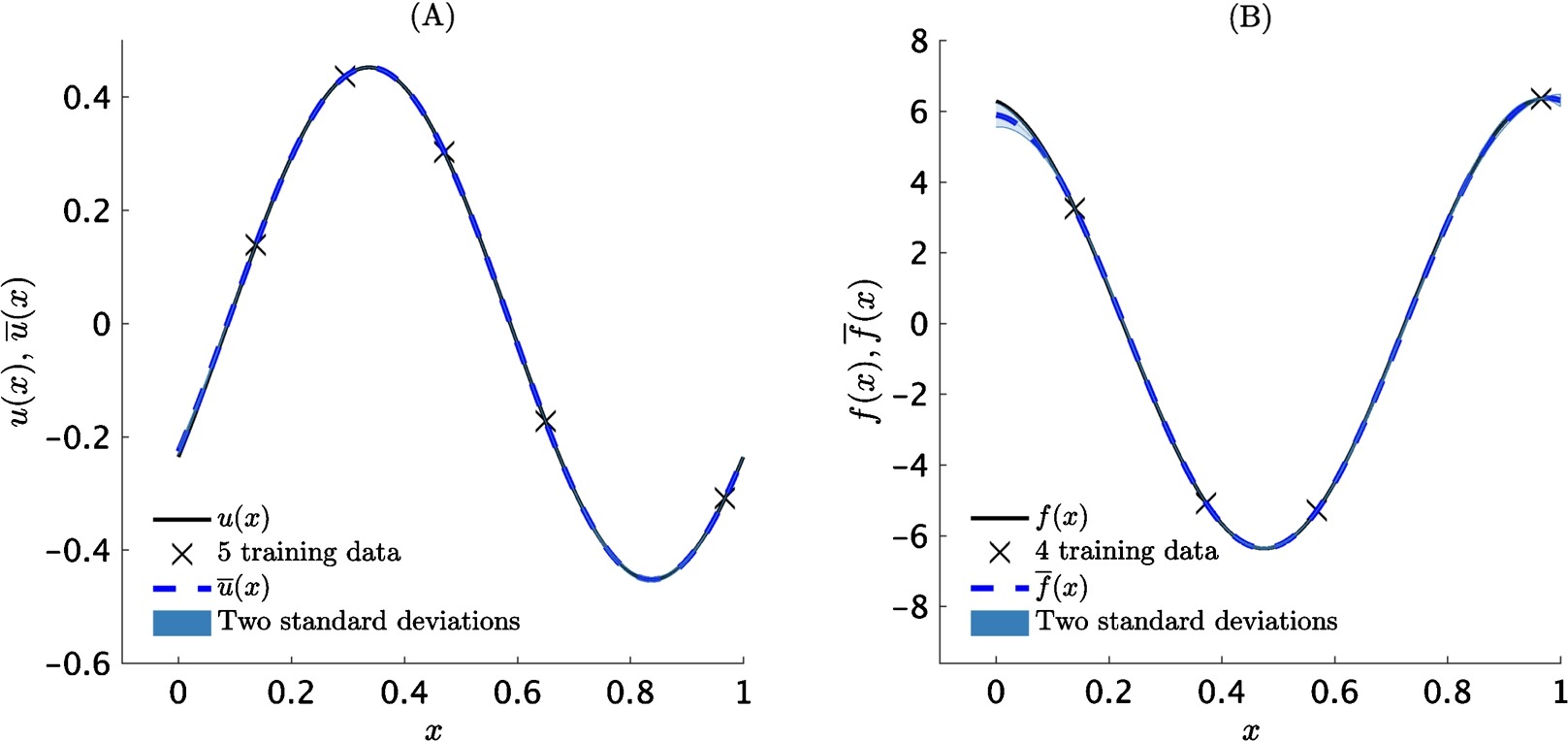
Fractional equation in 1D: (A) Exact left-hand-side function, training data, predictive mean, and two-standard-deviation band around the mean. (B) Exact right-hand-side function, training data, predictive mean, and two-standard-deviation band around the mean.
Example: Heat Equation
This example is chosen to highlight the ability of the proposed framework to handle time-dependent problems using only scattered space-time observations. To this end, consider the heat equation
Here, . The algorithm learns the parameter to have value of .
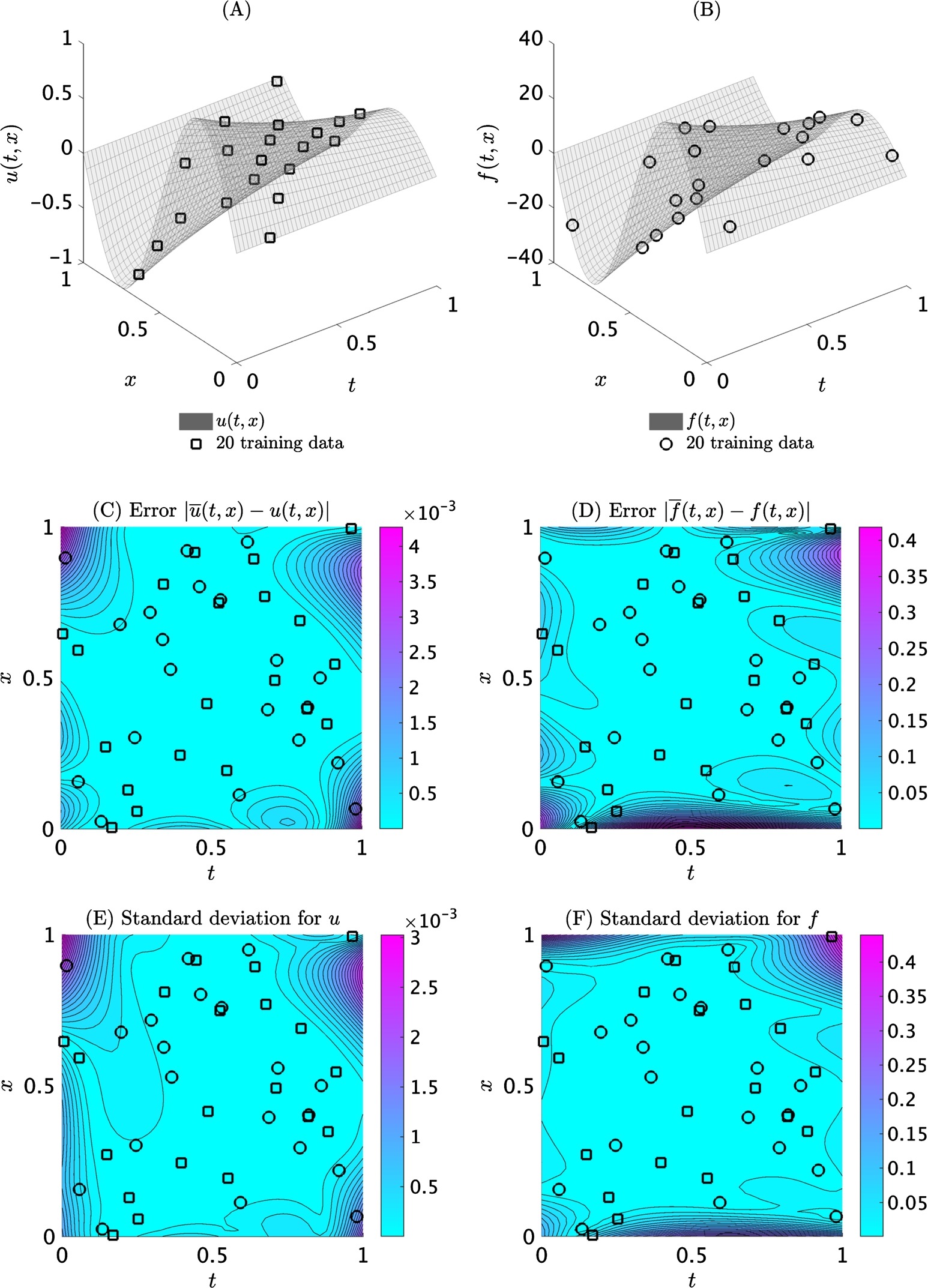
Heat equation: (A) Exact left-hand-side function and training data. (B) Exact right-hand-side function and training data. (C) Absolute point-wise error between the predictive mean and the exact function. The relative L2 error for the left-hand-side function is 1.25x10^-3. (D) Absolute point-wise error between the predictive mean and the exact function. The relative L2 error for the right-hand-side function is 4.17x10^-3. (E), (F) Standard deviations for the left- and rigt-hand-side functions, respectively.
Further Reading
For more information please refer to paper 1 and paper 2. The codes for these two papers are publicly available on GitHub.
All data and codes for this tutorial are publicly available on GitHub.
Citation
@article{raissi2016deep,
title={Deep Multi-fidelity Gaussian Processes},
author={Raissi, Maziar and Karniadakis, George},
journal={arXiv preprint arXiv:1604.07484},
year={2016}
}
@article{raissi2017inferring,
title={Inferring solutions of differential equations using noisy multi-fidelity data},
author={Raissi, Maziar and Perdikaris, Paris and Karniadakis, George Em},
journal={Journal of Computational Physics},
volume={335},
pages={736--746},
year={2017},
publisher={Elsevier}
}
@article{RAISSI2017683,
title = "Machine learning of linear differential equations using Gaussian processes",
journal = "Journal of Computational Physics",
volume = "348",
pages = "683 - 693",
year = "2017",
issn = "0021-9991",
doi = "https://doi.org/10.1016/j.jcp.2017.07.050",
url = "http://www.sciencedirect.com/science/article/pii/S0021999117305582",
author = "Maziar Raissi and Paris Perdikaris and George Em Karniadakis"
}