Author
Abstract
Modern datasets are rapidly growing in size and complexity, and there is a pressing need to develop new statistical methods and machine learning techniques to harness this wealth of data. This work presents a novel regression framework for encoding massive amount of data into a small number of “hypothetical” data points. While being effective, the resulting model is conceptually very simple and is built upon the seemingly self-contradictory idea of making Gaussian processes “parametric”. This simplicity is important specially when it comes to deploying machine learning algorithms on big data flow engines such as MapReduce and Apache Spark. Moreover, it is of great importance to devise models that are aware of their imperfections and are capable of properly quantifying the uncertainty in their predictions associated with such limitations.
Methodology
To address the most fundamental shortcoming of Gaussian processes, namely the lack of scalability to “big data”, we propose to use two Gaussian processes rather than one;
1) A Gaussian process in its classical sense whose hyper-parameters are trained using a “hypothetical dataset” and the corresponding negative log marginal likelihood. This Gaussian process is also used for prediction by conditioning on the hypothetical data.
2) A “parametric Gaussian process” that is used to generate the hypothetical dataset consumed by .
One could think of as the “producer” of the hypothetical data and as the “consumer” of such data. Therefore, never sees the real data, rendering the size of the real dataset irrelevant. In fact, is the one that sees the real data and transforms it into the hypothetical data consumed by .
Hypothetical Data
At iteration of the algorithm, let us postulate the existence of some hypothetical dataset with
Here, is the mean of the hypothetical data and is the covariance matrix. Moreover, , , and is the size of the hypothetical data. The size of the hypothetical data is assumed to be much smaller than the size of the real dataset . The locations of the hypothetical dataset are obtained by employing the k-means clustering algorithm on (or a smaller subset of it) and are fixed throughout the algorithm.
Consumer of Hypothetical Data
Let us start by making the prior assumption that
is a zero mean Gaussian process with covariance function which depends on the hyper-parameters . The hyper-parameters can be updated from to by taking a step proportional to the gradient of the negative log marginal likelihood
where . It is worth highlighting that we are using the mean of the hypothetical data in the formula for the negative log marginal likelihood rather than the actual hypothetical data . Moreover, predictions can be made by conditioning on the hypothetical data and obtaining
where and . In fact, for prediction purposes, we need to maginalize out and use
where
and
Producer of Hypothetical Data
Let us define a parametric Gaussian process by the resulting conditional distribution
The mean and the covariance matrix of the hypothetical dataset can be updated by employing the posterior distribution
resulting from conditioning on the observed mini-batch of data of size ; i.e.,
It is worth mentioning that and . The information corresponding to the mini-batch is now distilled in the parameters and . The algorithm is initialized by setting and where is some initial set of hyper-parameters. Therefore, initially .
Illustrative Example
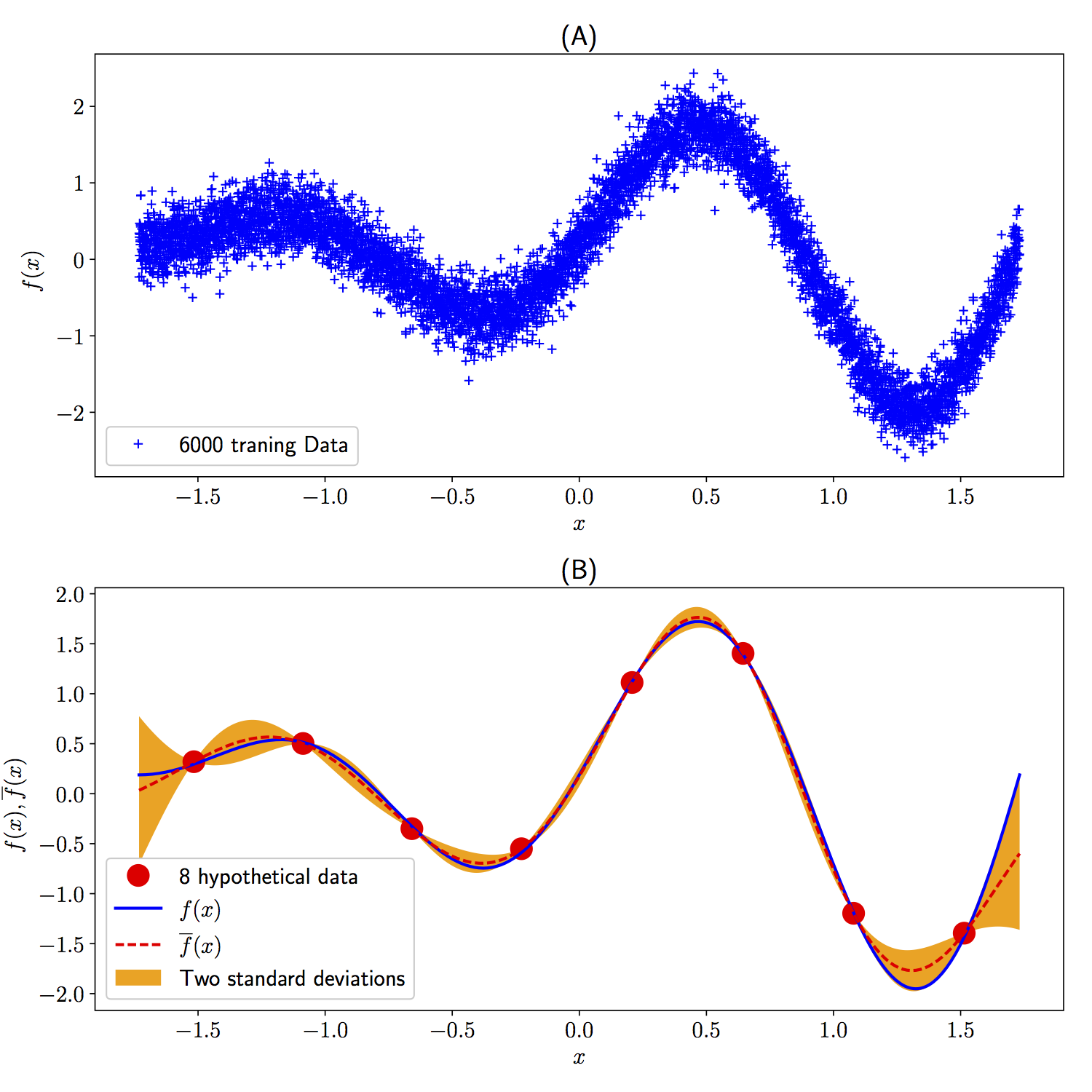
Illustrative example: (A) Plotted are 6000 training data generated by random perturbations of a one dimensional function. (B) Depicted is the resulting prediction of the model. The blue solid line represents the true data generating function, while the dashed red line depicts the predicted mean. The shaded orange region illustrates the two standard deviations band around the mean. The red circles depict the resulting mean values for the 8 hypothetical data points after a single pass through the entire dataset while mini-batches of size one are employed per each iteration of the training algorithm. It is remarkable how the training procedure places the mean of the hypothetical dataset on top of the underlying function.
Conclusions
This work introduced the concept of parametric Gaussian processes (PGPs), which is built upon the seemingly self-contradictory idea of making Gaussian processes “parametric”. Parametric Gaussian processes, by construction, are designed to operate in “big data” regimes where one is interested in quantifying the uncertainty associated with noisy data. The effectiveness of the proposed approach was demonstrated using an illustrative example with simulated data and a benchmark dataset in the airline industry with approximately million records (see here).
Acknowledgements
This work received support by the DARPA EQUiPS grant N66001-15-2-4055 and the AFOSR grant FA9550-17-1-0013. All data and codes are publicly available on GitHub.
Citation
@article{raissi2017parametric,
title={Parametric Gaussian Process Regression for Big Data},
author={Raissi, Maziar},
journal={arXiv preprint arXiv:1704.03144},
year={2017}
}