Author
Abstract
This is a short tutorial on the following topics in Deep Learning: Neural Networks, Recurrent Neural Networks, Long Short Term Memory Networks, Variational Auto-encoders, and Conditional Variational Auto-encoders. The full code for this tutorial can be found here.
Neural Networks
Consider the following deep neural network with two hidden layers.
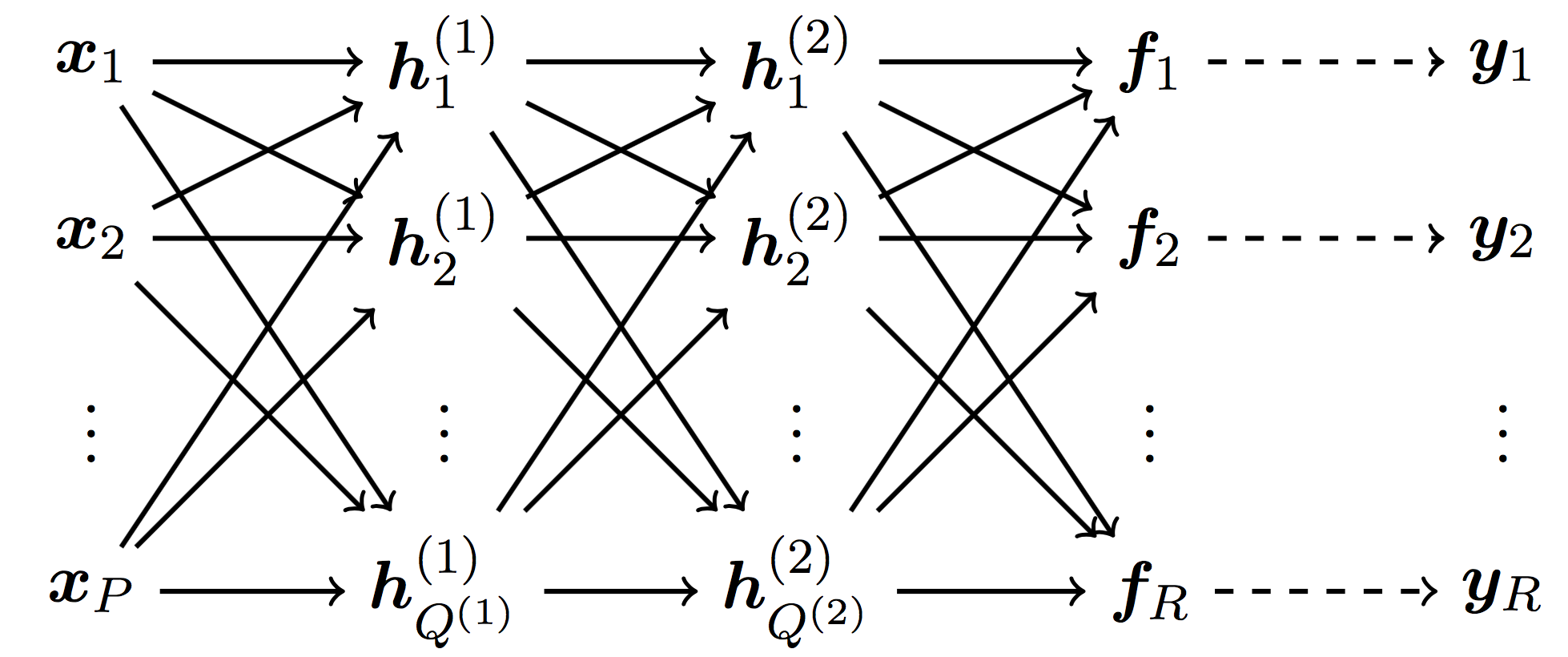
Here, denotes dimension of the input data . The first hidden layer is given by
where denotes dimension of the matrix
In matrix-vector notations we obtain with being a matrix of multipliers and denoting the bias vector. Here, is the activation function given explicitly by . Similarly, the second hidden layer is given by where is a matrix of multipliers and denotes the bias vector. The output of the neural network is given by with and . Moreover, we assume a Gaussian noise model
with mutually independent . Letting , we obtain the following likelihood
where diag and . One can train the parameters of the neural network by minimizing the resulting negative log likelihood.
Illustrative Example
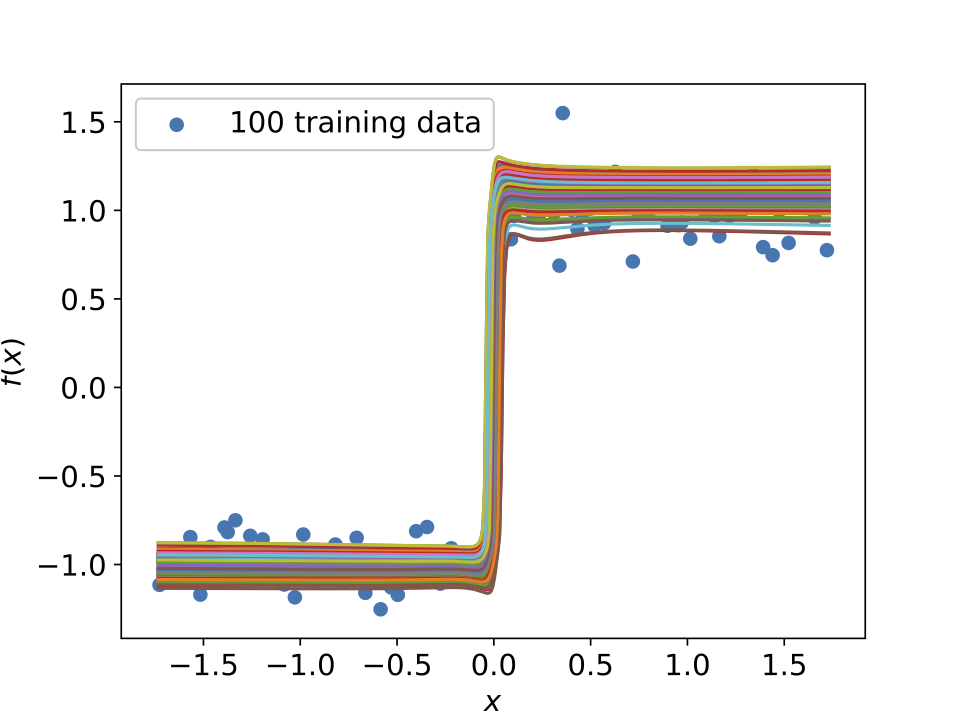
The following figure depicts a neural network fit to a synthetic dataset generated by random perturbations of a simple one dimensional function.
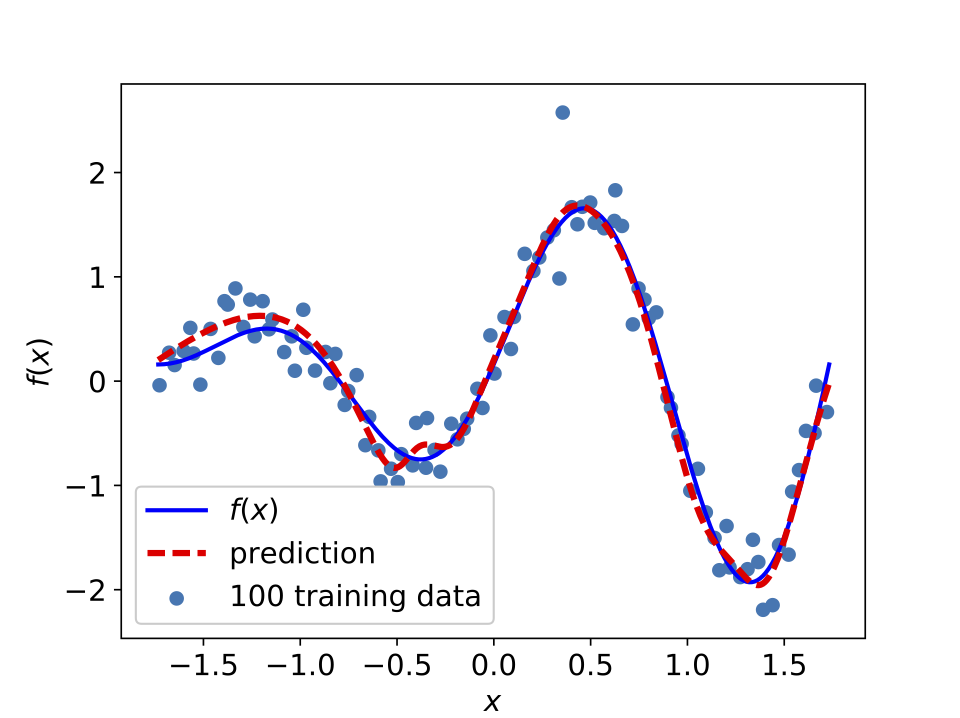
Neural network fitting a simple one dimensional function.
Recurrent Neural Networks
Let us consider a time series dataset of the form . We can employ the following recurrent neural network
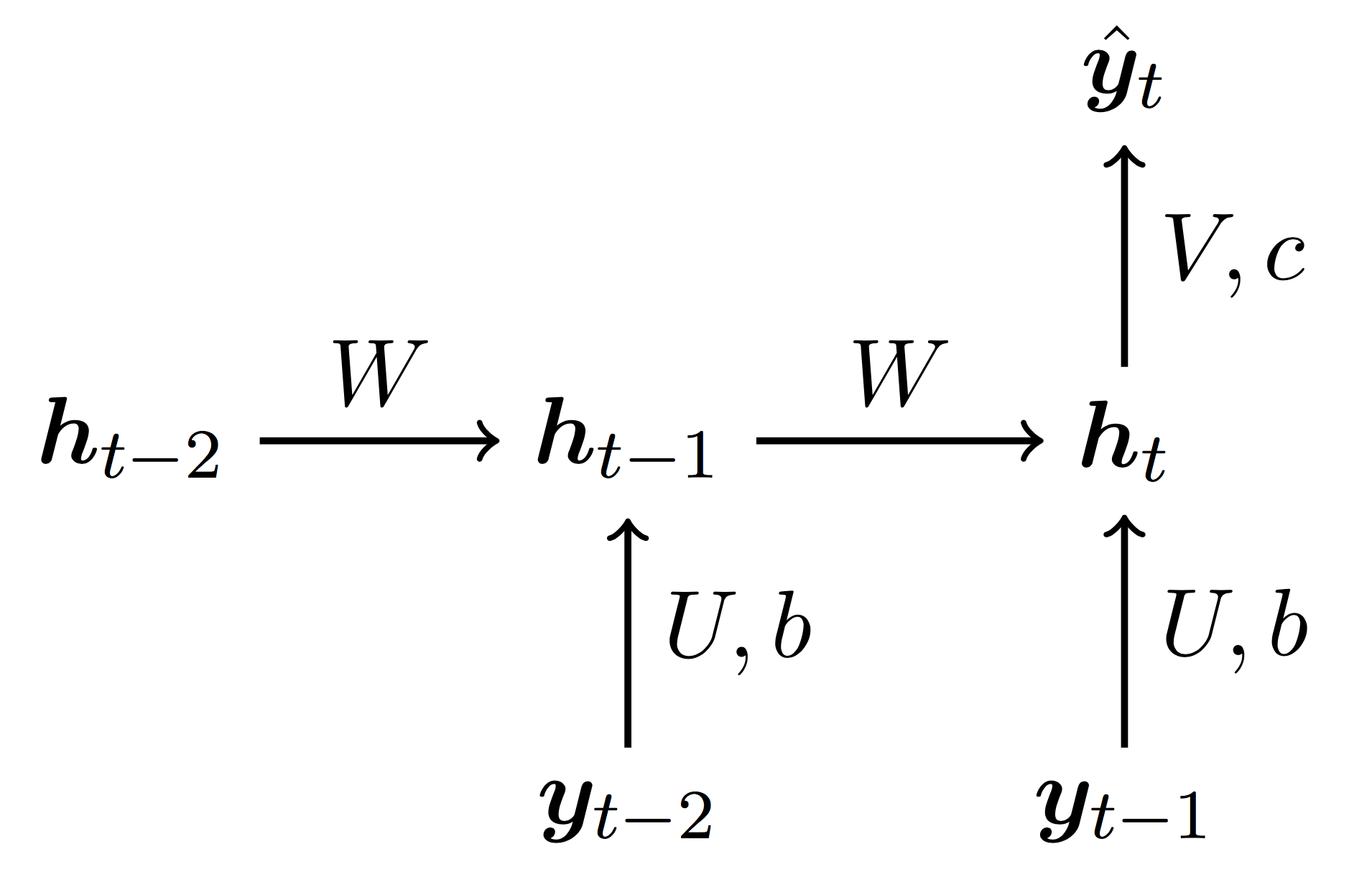
to model the next value of the variable of interest as a function of its own lagged values and ; i.e., . Here, , , , and . The parameters and of the recurrent neural network can be trained my minimizing the mean squared error
Illustrative Example
The following figure depicts a recurrent neural network (with $5$ lags) learning and predicting the dynamics of a simple sine wave.
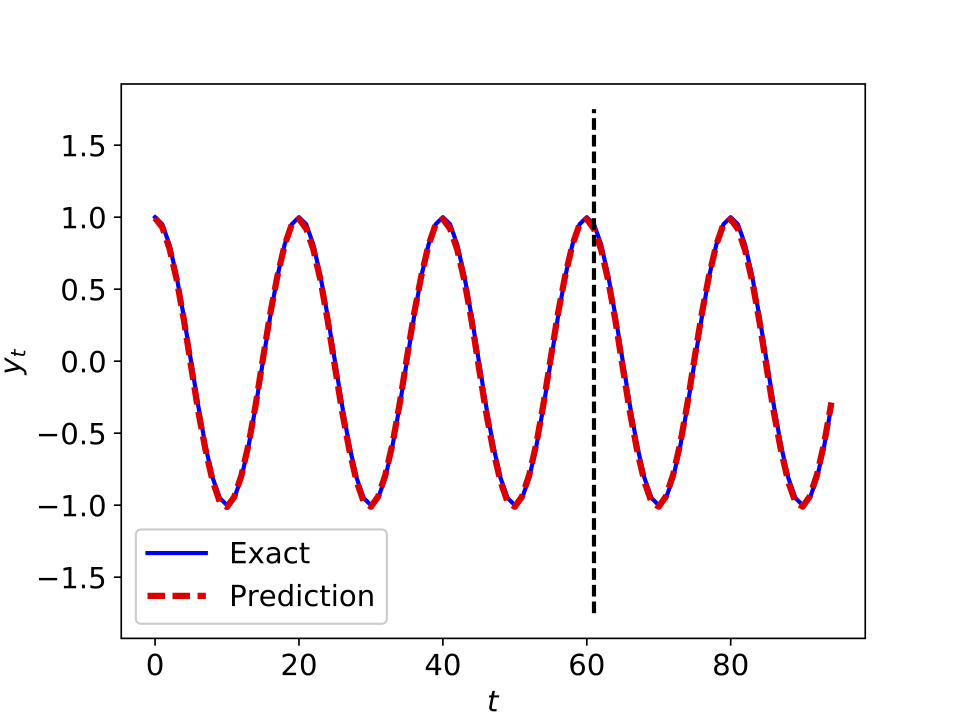
Recurrent neural network predicting the dynamics of a simple sine wave.
Long Short Term Memory (LSTM) Networks
A long short term memory (LSTM) network replaces the units of a recurrent neural network with
where
is the output gate and
is the cell state. Here,
Moreover,
is the external input gate while
is the forget gate.
Illustrative Example
The following figure depicts a long short term memory network (with $10$ lags) learning and predicting the dynamics of a simple sine wave.
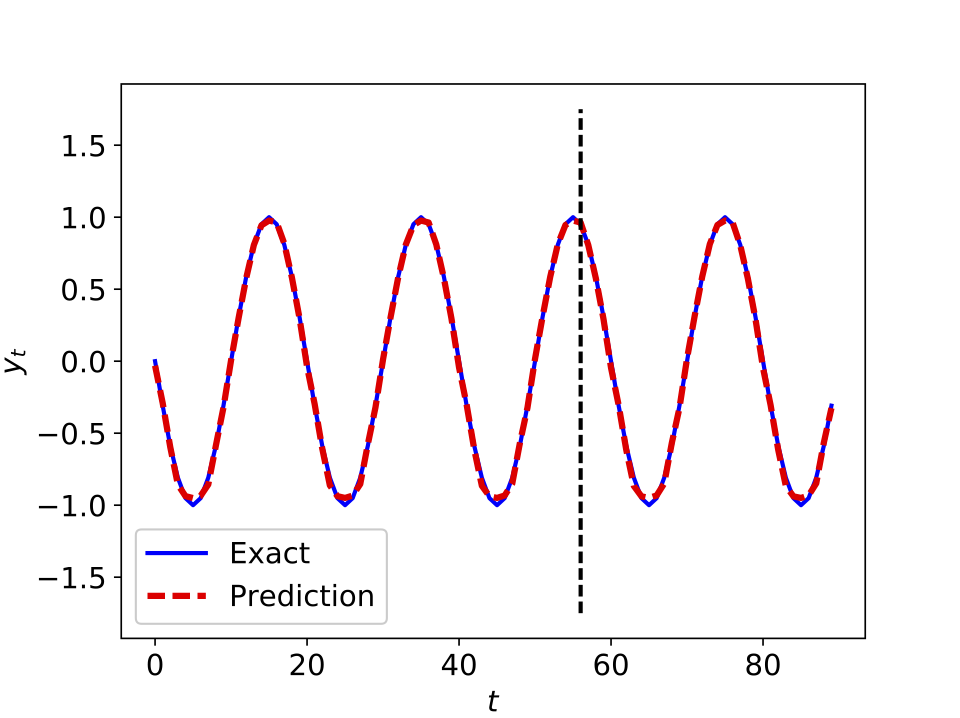
Long short term memory network predicting the dynamics of a simple sine wave.
Variational Auto-encoders
Let us start by the prior assumption that
where is a latent variable. Moreover, let us assume
where and are modeled as deep neural networks. Here, is constrained to be a diagonal matrix. We are interested in minimizing the negative log likelihood , where
However, is not analytically tractable. To deal with this issue, one could employ a variational distribution
and compute the following Kullback-Leibler divergence; i.e.,
Using the Bayes rule
one obtains
Therefore,
Rearranging the terms yields
A variational auto-encoder proceeds by minimizing the terms on the right hand side of the above equation. Moreover, let us assume that
where and are modeled as deep neural networks. Here, is constrained to be a diagonal matrix. One can use
to generate samples from
Illustrative Example
The following figure depicts the training data and the samples generated by a variational auto-encoder.
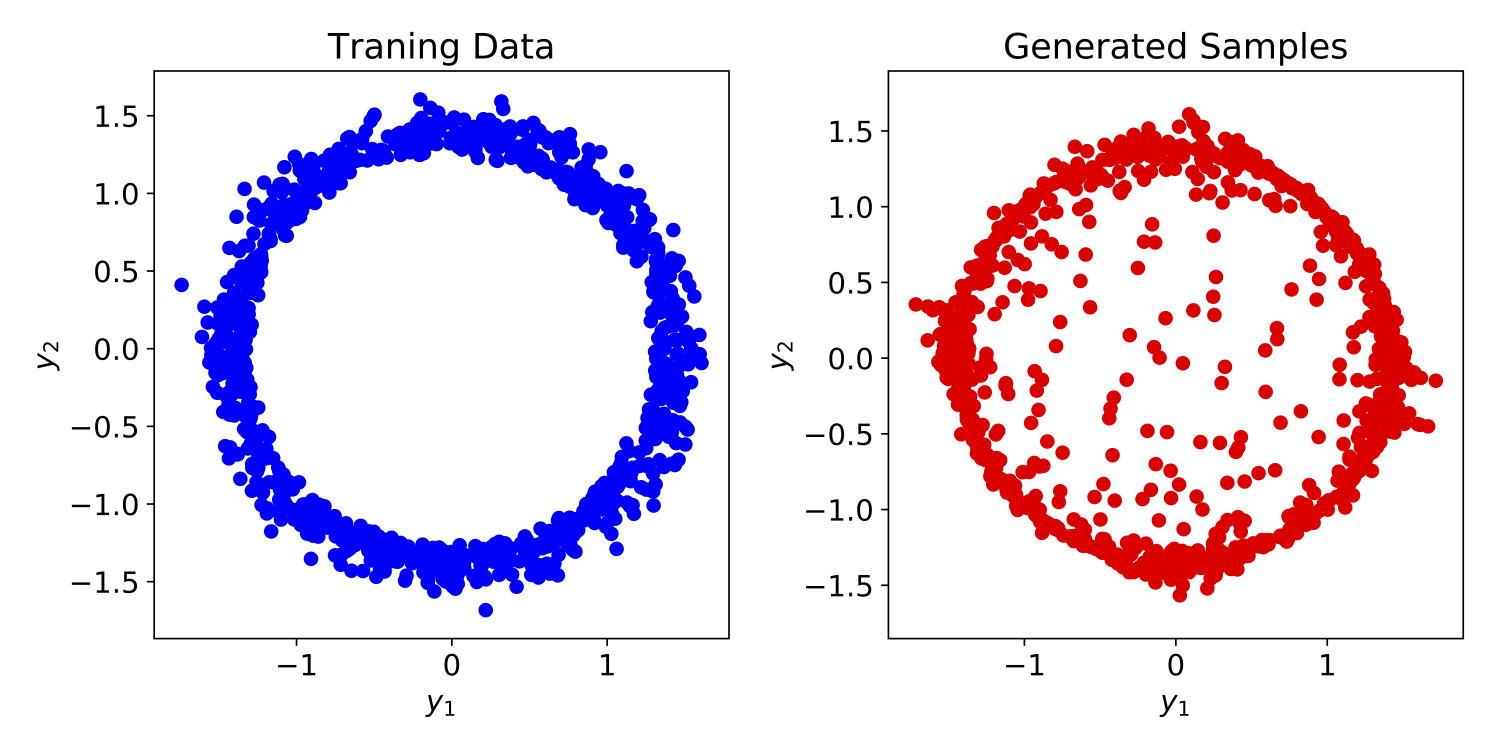
Training data and samples generated by a variational auto-encoder.
Conditional Variational Auto-encoders
Conditional variational auto-encoders, rather that making the assumption that
start by assuming that
where and are modeled as deep neural networks. Here, is constrained to be a diagonal matrix.
Illustrative Example
The following figure depicts the training data and the samples generated by a conditional variational auto-encoder.
Training data and samples generated by a conditional variational auto-encoder.
All data and codes are publicly available on GitHub.